So this week, we started push a little bit further on both mesh processing and shader creating.
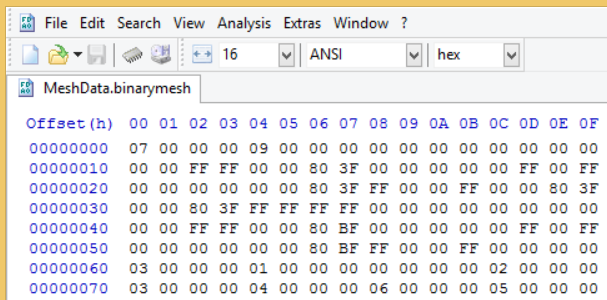
Above is a figure showing my whole binary file for a square and a triangle.
As you may see, the sequence of 4 pieces of data in my case is NumOfVertex, NumOfIndice, VertexData and IndiceData. The reason to put counts ahead is simply that their size is fixed. In the case of processing multiple lua meshes, we need to rewrite part of the file. If 2 counts comes first, then we just need to move IndiceData from its beginning because we will write in new VertexData, while previous VertexData doesn't need to be moved.
The reason number must come first is that they should be used to calculate the size of the data chunk. No one would know how much we should read unless we know how many corresponding data there are.
Binary data is fast in process because it's pure std library work with the minimum data size. It saves time when loading a scene in the game. It's also smaller in size. The more human readable an asset is, it's more likely to be large sized compared to its binary peer. When we ship a product build, we also want to save disk space for users. Human-readable assets has its advantage just as the name suggests. As asset author or engineers, we need to look into assets efficiently to modify assets. So that's necessary to have both binary and human-readable version of the same assets for our case.
My triangle lua mesh is 4096 bytes while binary mesh is just 56 bytes.
Here's my code loading binary mesh data into memory:
As you may see, the sequence of 4 pieces of data in my case is NumOfVertex, NumOfIndice, VertexData and IndiceData. The reason to put counts ahead is simply that their size is fixed. In the case of processing multiple lua meshes, we need to rewrite part of the file. If 2 counts comes first, then we just need to move IndiceData from its beginning because we will write in new VertexData, while previous VertexData doesn't need to be moved.
The reason number must come first is that they should be used to calculate the size of the data chunk. No one would know how much we should read unless we know how many corresponding data there are.
Binary data is fast in process because it's pure std library work with the minimum data size. It saves time when loading a scene in the game. It's also smaller in size. The more human readable an asset is, it's more likely to be large sized compared to its binary peer. When we ship a product build, we also want to save disk space for users. Human-readable assets has its advantage just as the name suggests. As asset author or engineers, we need to look into assets efficiently to modify assets. So that's necessary to have both binary and human-readable version of the same assets for our case.
My triangle lua mesh is 4096 bytes while binary mesh is just 56 bytes.
Here's my code loading binary mesh data into memory:
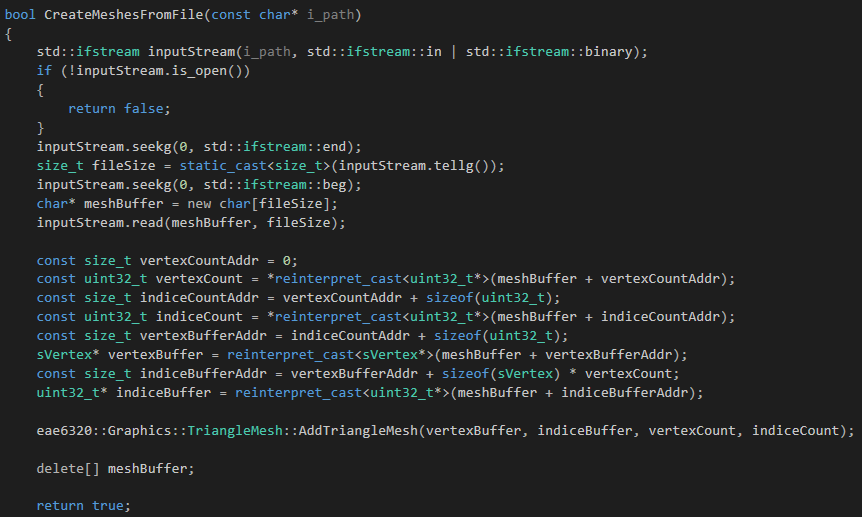
I also modified my AddTriangleMesh to static class that no longer holds instance of separate triangle mesh pieces.
Here's a picture showing how I load my shader file.
Here's a picture showing how I load my shader file.
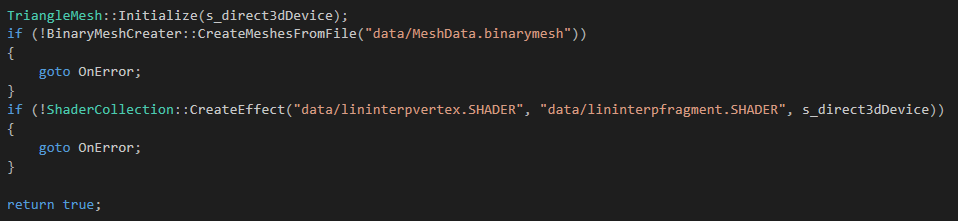
The class shader collection also contains a map keeping key-value pairs which represent effect name and effect instance. User of the class could create multiple effects with different name and set them during rendering call with their own name.
Here's how I call set effect in rendering code:
Here's how I call set effect in rendering code:

Simple and short enough. If a name is not given at creation, an effect instance will have a default name, this name will also be used as the default input of set effect method.
Here's a copy of my executable:
Here's a copy of my executable:
| assignment06.zip |
UPDATE:
So I made an inappropriate decision merging multiple binary file into one. Doing so means it's hard to have different effects for different meshes. I modified my TriangleMesh class back to preserving a static multimap keeping all mesh instances labeled with a name ("default" by default). DrawAllMeshes method is used to draw all meshes. DrawMeshesWithName method is used to draw all meshes with the same name.
Here's the new executable:
So I made an inappropriate decision merging multiple binary file into one. Doing so means it's hard to have different effects for different meshes. I modified my TriangleMesh class back to preserving a static multimap keeping all mesh instances labeled with a name ("default" by default). DrawAllMeshes method is used to draw all meshes. DrawMeshesWithName method is used to draw all meshes with the same name.
Here's the new executable:
| assignment06.zip |
 RSS Feed
RSS Feed
